End-to-End platform for
Continual Learning
with AI agents
Deploy. Train. Repeat.
Build AI agents and continuously train them on production traffic or let Claude Code do it for you.
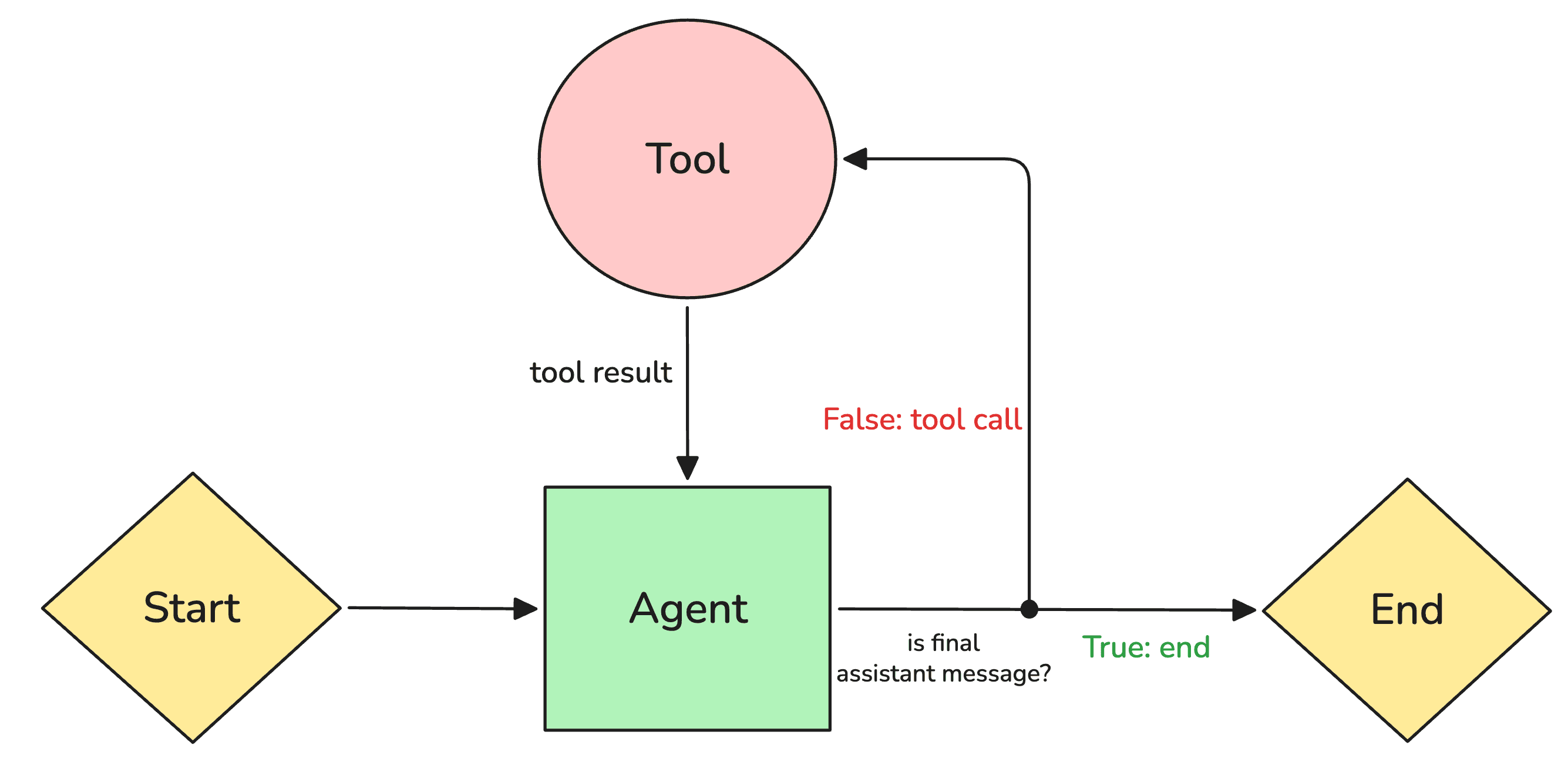
How it works
Train Efficiently
Fastest Training,
Cheapest Compute
Achieve maximum throughput for LLM finetuning with LoRA and significantly reduce compute costs.



Tokens per second

Open Source Support
Wide Model Support
Support for the best open source models like Qwen,
DeepSeek and GPT-OSS.

Agent Training Observability
Advanced Telemetry
Intelligent telemetry to evaluate, monitor
and iterate on AI Agent LLM applications.
Multi turn Intelligence
Long Horizon Tasks
Train on 32k to 1 million size context using RLMs.
Build vertical agents for multi-turn and long-running tasks.
Own your Weights
Deploy Anywhere
Download your model and deploy
your AI agents with ReinforceNow or your preferred cloud provider.







Predictable Performance
Focus on finetuning your AI agents
instead of dealing with:

OOM errors
Hefty debug bills

GPU infrastructure
Performance optimizations
Get started in three easy steps.
1.
Set up your
environment
2.
Add your data
in JSONL

3.
Press Enter
FAQ
More details you might want to know:
ReinforceNow handles reinforcement learning infrastructure, experiment orchestration, and agent versioning.
You focus on agent logic, data collection, and rewards, then run training and evaluation via the CLI.